

Web Scraping: Data For Everyone
Let's start this off with some important clarifications. Nothing in this article should be construed as legal advice or endorsement from me. This is just an exploration of the techniques and considerations in web scraping based on my experience and knowledge. Make sure to do your own research and always abide by the laws of your jurisdiction.
⸺
Before we delve into the details of web scraping, I strongly recommend that you have a basic understanding of what data is about. If you need a refresher, my previous article provides a good starting point.
So we know what Data is, but where does it come from? It could be commercial, either sourced from data providers who produce it, or data brokers who resell it. It could be public data made available by governments, institutions, and other such organizations. User-generated data is another abundant source — this could comprise non-personal data such as weather reports, traffic updates, or personally identifiable information (PII) such as location, purchasing logs, and so on.
Then there is web scraping. It provides you with a way to collect data that is available on a website - or really, anywhere on the internet. This process involves interacting with websites using a “scraper”, that will open the website on your behalf and collect the information you need accordingly. This article will get you started in this world.
But despite how complicated it might sound, web scraping isn't the exclusive domain of tech gurus and AI scientists. In fact, you'd be surprised by the diverse set of professions and industries that make use of it on daily basis. The examples below are meant to inspire you and are not exhaustive by any means.
- Travel Fares and Availability: Travel agencies and individual travelers can use web scraping to keep track of flight and hotel prices, find the best deals and book at the most optimal times. This can also be useful for predicting future price trends and planning trips accordingly.
- Real Estate Analysis: Real estate companies and investors scrape property listings for data on prices, locations, features, and market trends. This data can help in making investment decisions and spotting emerging trends in the property market.
- Brand Monitoring: Companies can scrape web data to monitor how their brand is perceived and discussed across the internet, keeping track of online reviews, news mentions, and social media comments.
- SEO Optimization: SEO professionals use web scraping to keep track of their website ranking on various search engines, monitor technical issues, track backlinks, and analyze content for keyword optimization.
- Competitive Analysis: Businesses and e-commerce shops scrape competitor websites to keep tabs on their product offerings, pricing strategies, or any other market activities. These insights are integral to staying competitive, adjust pricing strategies and making informed business decisions.
- Lead Generation: Sales and marketing teams scrape the web for contact information and other relevant data to generate potential leads.
In essence, anyone who needs to collect and analyze data from the web on a large scale can benefit from web scraping. All it takes is a bit of know-how, the right tools, a clear purpose, and an understanding of the ethical and legal boundaries.
How does it work in practice?
Let’s look at a simple scraper. This particular example is built with code, but it doesn't always have to be.
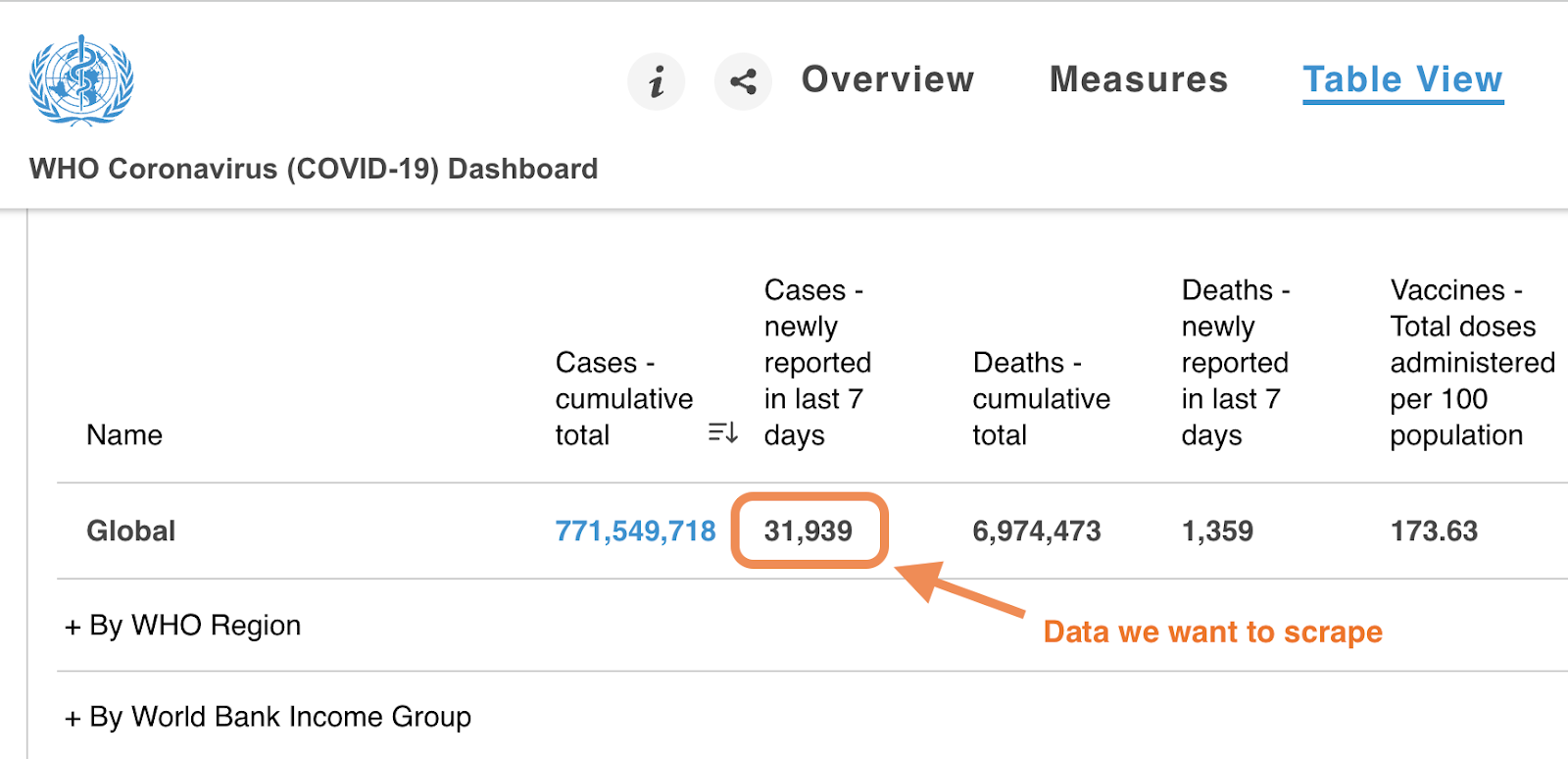
Our goal in this example is to collect last week’s number of COVID cases over the last week from the WHO website.
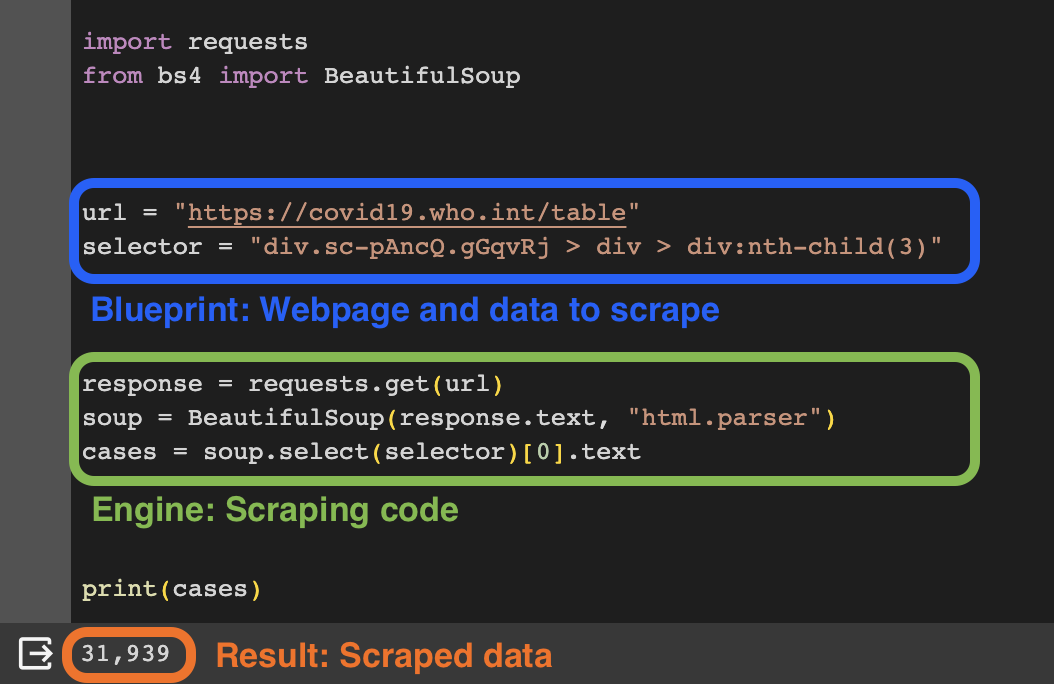
This is our (very minimal but fully functional) scraper. I ran it and you can see the result at the bottom of the screenshot above.
What’s happening here?
The blue part of the process is your blueprint. Here, you pinpoint the webpage and specific data you're interested in. You'll need a URL, which is like the address of the webpage, and a selector, which works like a detailed map, leading you to the exact data spot within the webpage.
The green part is the engine, where your blueprint gets into action. This is where your scraper actually loads the webpage using the URL and extracts data as specified by your selectors from the blueprint.
This two-phase process - blueprint and engine - is a typical framework in most data scraping techniques, regardless if they require coding knowledge or not. Simply put, the blue section is your 'What' (What data to scrape?) and the green section is your 'How' (How to get it?).
Both are determined by which scraping technique you choose. And selecting the right one hinges on your specific needs. Each comes with its unique strengths and quirks - engine capabilities, complexity of the blueprints. In a nutshell, it's about finding your perfect fit, probably from one of the categories below.
Manual Data Entry
Yes, the simplest way is still to manually copy and paste the data from the web page to your destination. This is absolutely fine, even recommended for small tasks but quickly becomes impractical for larger ones.
Scraping is a form of automation, and it might not be wise to automate a task if it is relatively short, or non-repeating. If you do want to automate, then read on.
Scraping with code
You can write scripts like in the example I showed you earlier to collect data from website pages, or by directly connecting to the website's servers. This requires coding knowledge and understanding of the webpage's HTML structure or the server's API documentation, but can get easier by leveraging tools or even scrapers made by other people.
The two approaches, HTML and API, are not mutually exclusive. Sometimes you end up using them together.
Using HTML
One consideration here is in terms of complexity. In the previous example, we only had to download the content of the web page. The data we wanted could be found in the page's HTML, as long as we could locate it there. That was a straightforward case I hand-picked to illustrate the scraping process, but seldom representative of the real world.
In many cases, simply downloading the content of a webpage is not enough. Some websites require you instead to simulate loading it in a browser first, so that the page retrieves additional data or performs some processing before you can access the data you're after. While being the most flexible approach, this kind of scraping slows you down and has more inherent complexity to it. Solid choices in this space are:
Pure HTML-based
Cheerio (JS)
Scrapy (Python)
BeautifulSoup (Python)
Browser-based
Browser options are available for most programming languages.
Using the API
Sometimes, the data you're looking for can be obtained directly using an API provided by a website. What's an API you might ask? Oversimplifying here, an API is a data-only version of the website. Perfect you might say, so why don't we always use APIs?
First we need to distinguish two kinds of APIs, each with unique challenges
Public API
A public API is offered by the website explicitly to be used by others to interact with the website with a program. These APIs are subject to explicit terms of service, often have clear rate limits, and sometimes are commercial in nature (you need to pay the website to make use of it). Popular public APIs are available from Meta, Twitter, Reddit, Github and others as well.
Why don't we always use them?
Public APIs are the best option if it works for your use case. They also clarify any ethical or legal ambiguity. It's the purest form of data available to you, but it's not always possible or realistic to use them for many reasons:
- Most websites don't have a public API, or conditions to access it are out of your reach.
- Even though the website shows the data you need, the public API might not provide it
- Not always reliable. (see Twitter and Reddit API pricing and availability debacles)
- Available data gets removed on a regular basis depending on the company's whims.
- Learning curve for each API, difficult to juggle multiple websites at once.
- Custom code needed for each API with a maintenance cost.
Private API
A private API is similar to a public API functionally, but it was created for the sole purpose of powering the website, and is not intended for external use. Nevertheless, and even though it most likely breaks the terms of service of any website you would scrape this way, there are some people doing it. Instagram or financial APIs for example are popular in this space.
Why don't we always use them?
While private APIs are the closest you will get to a pure data version of the website, since they are responsible for providing that data for the website to display, the main downside of using them is running afoul of the website's Terms of Service, that's if you're not breaking the law in your jurisdiction entirely. Some other times it might be okay. Do extensive research and consult with a lawyer possibly before heading down this path.
No-Code Solutions
Several tools and browser extensions allow for easier data collection. These include web scraper extensions, automation recorders, and no-code scraping platforms. The space is so vast it requires its own dedicated article which I will publish in the future.
This is also where my company Monitoro operates, although the problems it solves are very related but not exactly about scraping.
Where to start
So many options, right? Where do you even start?
Start with a goal first. Your actual objective is rarely to hoard data, but is an outcome that you want to achieve, and for which you need the data. Then you can look at the diagram below to decide which path to follow to get the data you want.
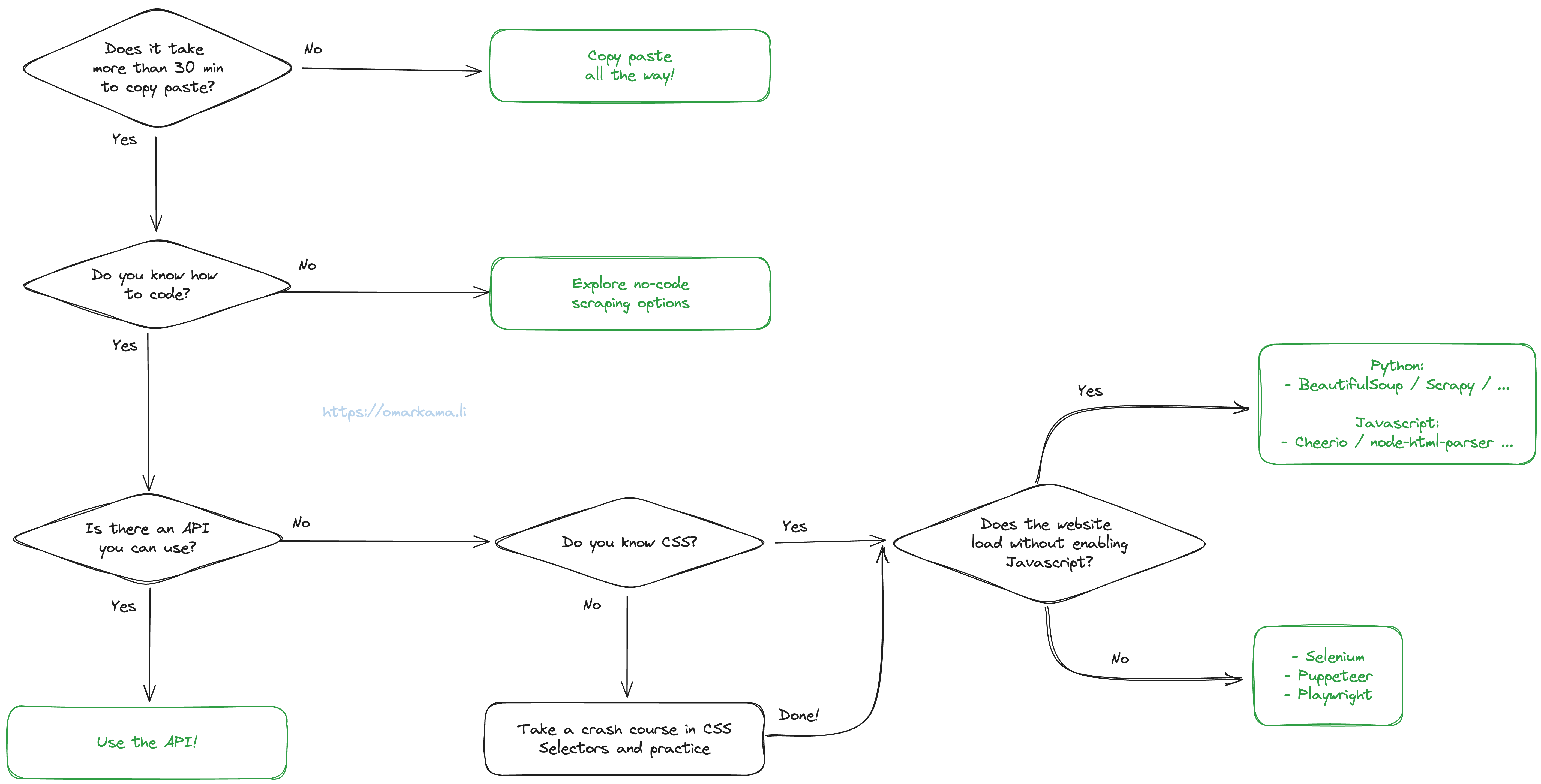
More Tools Of The Trade
The discussion about scraping would not be complete without mentioning annex tools that are commonly used when encountering certain challenges.
- Proxies: When your activities might result in your IP getting blocked, proxies allow you to distribute requests across multiple IP addresses, thereby reducing the likelihood of detection and blockage. There are different kinds of proxies, depending on the nature of the IP that you get. IPv6 and Datacenter IPs are the lowest quality usually, while residential IPs deliver better results.
- Anti-Captcha: Captchas are designed to identify and block bots. Anti-Captcha tools can help solve these challenges and allow your scraping activities to continue. This is mostly built on top of cheap labor, or more recently on the latest advancements in AI technology. It is either a gray area business, or a cat-and-mouse games with the latest Captchas becoming hard to solve even for humans, let alone for humans with impairments.
There's recent a move in the direction of what's called Proof-of-Work Captcha [1], which relies less on human-like capabilities and focuses on costing resources to increase the cost on accessing the website proportionally to the intensity of the access.
[1]: mCaptcha
Conclusion
This covers our initial foray into the basics of web scraping, where we looked at what scraping is, some of its use cases, and how it works in practice. This is only scratching the surface, but before we dive too deep into scraping techniques, we will first look at the ethical and legal considerations to make in the next post in the Data series. This will help you build a comprehensive understanding of the field that is not limited to the technical aspects.
Thank you for reading, and see you in the next part of the series!
Related posts
Interested in collaboration?
I'm open to research partnerships, compute collaborations, or contributing to low-resource language AI.
Get in touch